
Swish Vs Mish: Latest Activation Functions
In this blog post we will be learning about two of the very recent activation functions Mish and Swift. Some of the activation functions which are already in the buzz. Relu, Leaky-relu, sigmoid, tanh are common among them. These days two of the activation functions Mish and Swift have outperformed many of the previous results by Relu and Leaky Relu specifically. Let us move on and get more into it!!
Importance of activation functions
The major purpose of activation function in neural networks is to introduce non-linearity between output and the input.
They basically decide when to fire a neuron and when to not. If we do not use activation fucntion, there will be a linear relationship between input and output variables and it would not be able to solve much complex problems as a linear relationship has some limitations. The main objective of introducing a activation function is to introduce non-linearity which should be able to solve complex problems such as Natural Language Processing, Classification, Recognition, Segmentation etc.
The figure below shows some of the very popular activation functions.
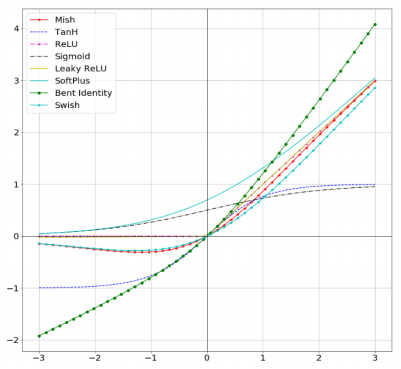
ReLU
ReLU is rectified linear unit activation function. It is defined as for x > 0, 0 otherwise.
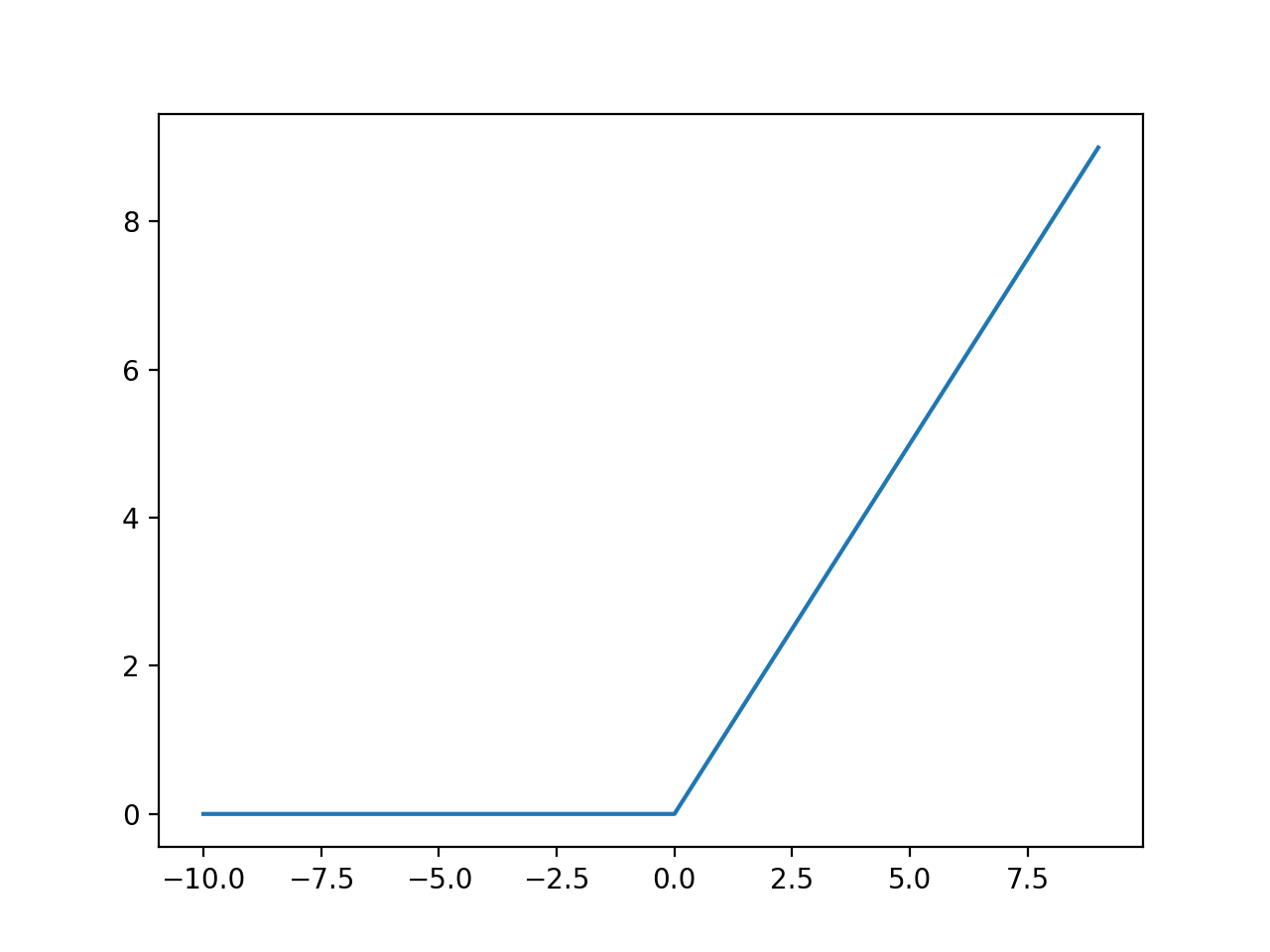
From the above figure we can see that ReLU has 0 gradient for all x < 0, it means that it would not activate all neurons at a time and very few neurons will be activated making it sparse and thus cost efficient and easy for computation.
Advantages of ReLU
-
We can observe that for x>0 ReLu has constant gradient, which reduces the chance of vanishing gradients at any point of time. This property also results in faster learning.
-
For all x <= 0 the gradient is zero and hence less number of neurons will be fired which will reduce overfitting and is also cost efficient.
-
Better convergence performance as compared to other activation fucntions.
Disadvantages of ReLU
- The main disadvantage of ReLU is the dying ReLU problem. A ReLU neuron is dead if it is stuck in the negative side and always outputs zero. It is also impossible for the neuron to recover bcak then.
Swish
It was discovered by the people of Google Brain in 2017. It is basically a gated version of sigmoid activation function.
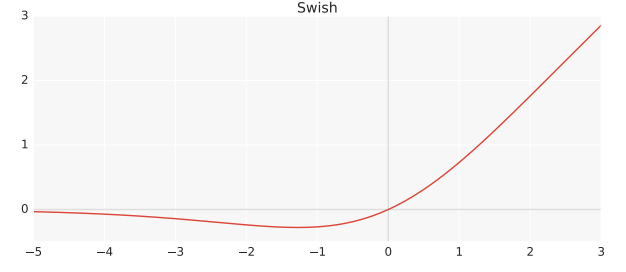
The formula of swish is where
is either a constant or trainable parameter. When
, swish becomes scaled linear function. When
tends to
, swish becomes ReLU function. The simple nature of swish and its resemblance with ReLU has made it popular and it has been replaced by ReLU in many neural networks. A simple replacement of ReLU by Swish suggests improvement in classification accuracy on ImageNet by 0.9 % and around 0.6% for Inception ResNet v2.

Like ReLU, Swish is unbounded above and bounded below. Swish is smooth and nonmonotonic. In fact, the non-monotonicity property of Swish makes it different from most common activation functions.
Advantages of Swish
- In very deep networks, swish achieves higher test accuracy than ReLU.
- For every batch size, swish outperforms ReLU.
- Non monocity property i.e for all x < 0, swish is neither decreasing nor increasing function.
Now that we have completed understanding what Swish is let us move to Mish activation fucntion and see how it works!
Mish
Mish is also one of the recent activation networks and is given by the formula where
. Most of the experiments suggest that Mish works better than ReLU, sigmoid and even Swish.
The following is the graph of Mish activation fucntion.
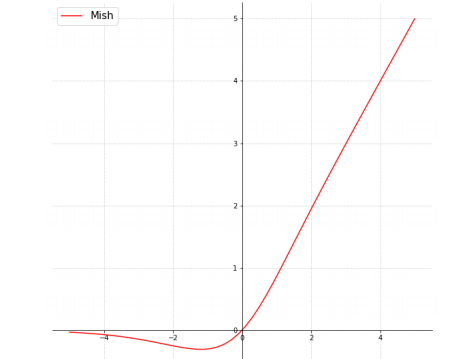
Like both Swish and Relu, Mish is bounded below and unbounded above and the range is nearly [-0.31, ).
Advantages of Mish:-
-
Being unbounded above is a desirable property for any activation function since it avoids saturation which generally causes training to drastically slow down due to near-zero gradients.
-
Being bounded below is also advantageous because it results in strong regulariation effects and reduces overfitting.
-
ReLU has an order of continuity as zero i.e it is not continuously differentiable and many cause some problems in gradient based optimization which is not in the case of Mish.
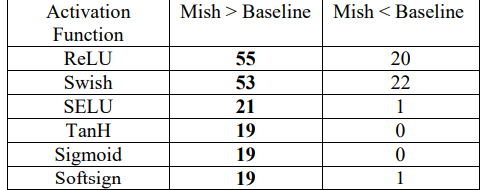
Summary of Properties of Mish
The following table shows the summary of all the properties of Mish.
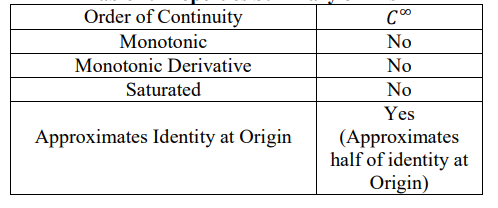
Comparsion between Swish And Mish
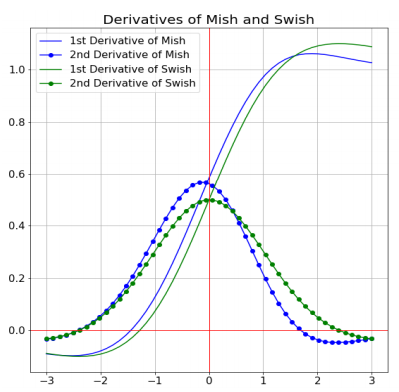
The figure below shows the comparison between the derivatives of the activation functions Mish and Swish. We study the nature of the graphs and some results about them.
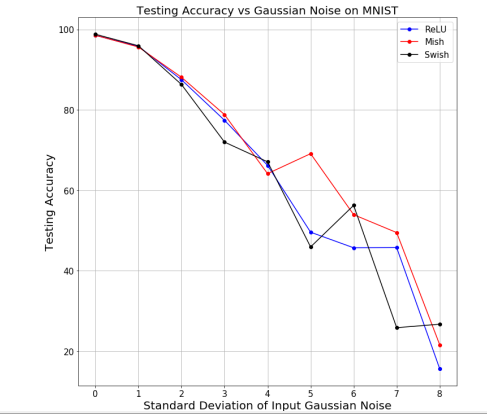
- Mish also outperforms in case of Noisy Input conditions as compared to other activation functions.
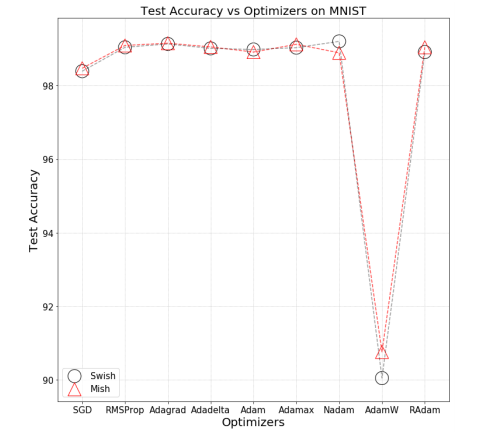
- Test accuracy v/s optimzers for Mish and Swish show that there is less drop in accuracy in case of Mish than Swish.
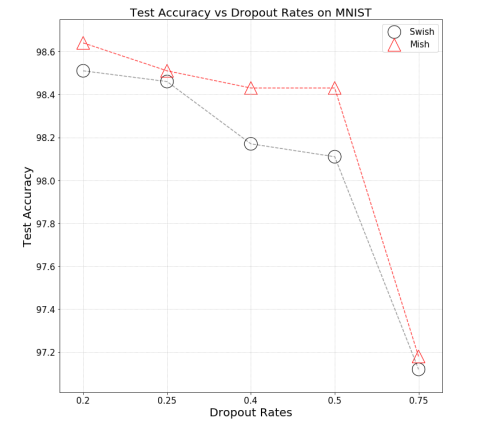
- Dropout is a fundamental process used in Neural Network Training to avoid Overfitting. Mish is shown to have a consistent improvement over Swish using different Dropout rates from 0.2 to 0.75 for a single dropout layer in a 4-layered network.
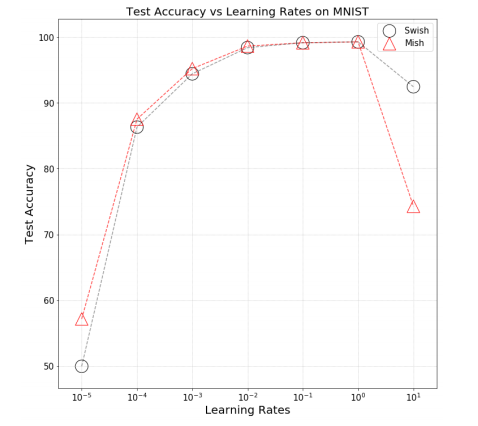
- Test Accuracy verus Learning rates for Mish and Swish also show that Mish Outperformed Swish in many ways.
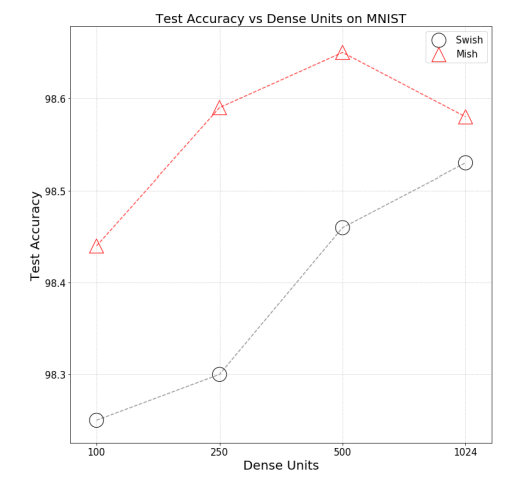
- It has also been observed that when the width of the neural network is increased i.e the number of neurons in a layer increased from 100 o 1024 in case of MNIST and CIFAR-10 classification, the test accuracy was always higher in case of Mish then Swish.
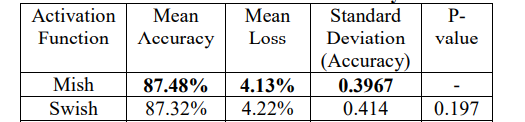
- The table below shows the test summary of mean acuuracy, mean loss and some other details abput Mish and Swish and Mish outperforms Swish in all of the parameters.
- A comparison of benchmark summary of Mish over other activation function, keeping the other parametres fixed show that Mish outperforms all the other activation functions.
Mish and Swish in tensorflow and Pytorch
